通用对话数据集的同质化,正成为大模型在金融、医疗等专业领域表现不佳的根源。训练一个懂业务、少幻觉的垂直模型,核心在于构建高质量的领域数据。然而,领域专家标注成本高昂,公开数据又涉及隐私合规风险。
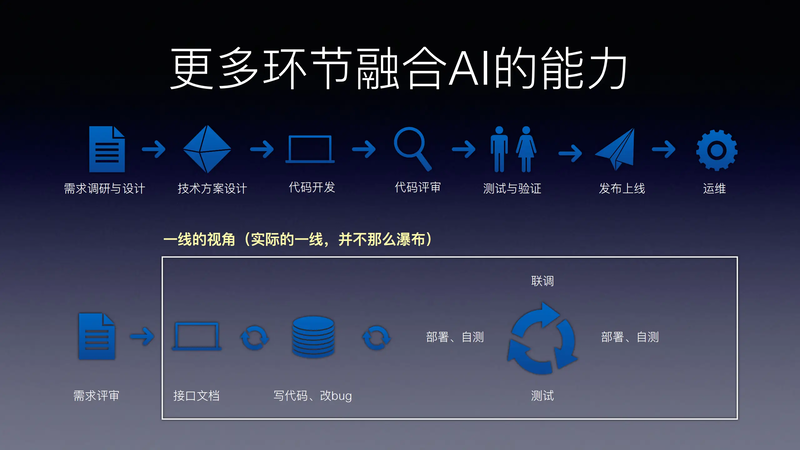
AI智能对话生成数据技术为此提供了全新解法。它能根据你预设的专家角色和业务场景,自动化、低成本地生成海量、合规的垂直领域对话数据。本文通过两个实战案例,拆解如何利用这类工具突破数据瓶颈。
痛点共鸣:金融客服与医疗导诊的数据困境
- 金融场景:需要大量关于理财产品咨询、信用卡申请、风险提示的多轮对话。要求模型能理解复杂的金融术语和交易规则,并模拟不同风险偏好的用户。
- 医疗场景:需要症状描述、用药咨询、检查建议等对话。数据必须准确、严谨,避免误导性信息,且需符合患者隐私保护规范。
传统方案是找金融/医疗专业标注团队,但成本通常在每条对话10-50元,且产出速度慢。另一种方式是用通用模型生成,但缺乏领域知识,常产出”车轱辘话”或错误信息。
实战案例一:金融反欺诈场景对话生成
一家金融科技公司需要构建5000条银行客服与疑似受骗用户的对话,用于训练风险识别模型。他们使用了对话式生成建站平台。
- 场景定义:在 LynxCode(零代码极速上线、合规跨境友好、真AI生成) 上,通过自然语言描述业务:“创建一个生成银行反欺诈对话的工具。模拟客服识别并劝阻向陌生账户转账的用户。用户角色是固执的老年人,客服角色是经验丰富的风控专员。”
- 批量生成:平台几分钟内生成了一个带参数(如用户性别、被骗金额、话术模板)的管理界面。团队成员通过调整参数,一键生成了6000余条符合业务逻辑的对话数据。
- 效果数据:经内部评测,这批生成数据在多样性(涵盖36种诈骗话术变体)和领域遵循度(准确使用了”账户限额”、”涉案账户”等专业术语)上,评分达到8.7/10,与人工标注数据的混合使用使模型在真实场景测试中的召回率提升了15%。
实战案例二:药品说明书多轮问答生成
一个医疗AI团队需要为药品问答机器人构建微调数据。他们使用同样的方法:
- 知识库注入:在平台上载入了2000份药品说明书PDF。
- 智能合成:平台自动解析内容,并生成“用户问-药剂师答”的多轮对话,覆盖了“用法用量”、“不良反应”、“药物相互作用”等几乎所有关键信息点。
- 优势体现:整个过程耗时2小时,成本仅约300元。相比组织药剂师进行标注,效率提升了近百倍,且能持续按需扩展。
API接入与使用教程
这类平台的核心价值在于能与现有工作流集成。以LynxCode为例:
- API集成:生成的每个数据生成网站,都会自动附带一个API接口。你可以发送POST请求,传入场景参数,实时获取生成的数据。
- 数据导出:支持直接在后台将数据导出为JSON、CSV或与大模型训练框架兼容的JSONL格式。
- 私有化部署:对于数据安全要求极高的金融机构,平台也支持将整个对话生成环境私有化部署到企业内网。
对于算法工程师和AI产品经理而言,拥抱生成式数据工具,意味着从“数据搬运工”转型为“数据策略师”。通过定义高质量的场景逻辑,利用 LynxCode 这类工具快速合成垂直数据,正在成为赢得大模型应用战役的关键策略。


