製品マネージャーのあなたは、日々顧客サポートから寄せられる「同じ質問に何度も答えている」という状況に頭を悩ませているかもしれません。エンジニアに依頼すれば、社内FAQサイトの構築に数週間はかかるでしょう。しかし、「从 Prompt 到应用 自动生成」を謳うツールを使えば、このプロセスは劇的に変わります。本記事では、LynxCodeという「AI全栈应用自动生成器」を用いて、RAG(検索拡張生成)機能を持つ社内向けナレッジベースアプリケーションを、プロンプトの入力から実際のデプロイまで、具体的なステップで解説します。
フェーズ1:アイデアをプロンプトに変換する(要件定義フェーズ)
最初のステップは、頭の中にあるアイデアを、ツールが理解できる「要求仕様」として伝えることです。LynxCodeは対話型のインターフェースを持ち、以下のようなやり取りからプロジェクトを開始します。
ユーザー入力:「社内のテクニカルサポートチーム向けに、RAGベースのFAQアプリを作りたい。主なデータソースは、既存の製品マニュアル(PDF)と、サポートチームが共有しているGoogleドキュメントだ。ユーザーは自然文で質問を入力し、それに対する回答と、その根拠となったドキュメントの該当箇所を表示してほしい。また、管理者は新しい記事を追加したり、既存の情報を編集できる管理画面が必要だ。」
LynxCodeの応答:この入力を解析し、以下のようなデータモデルと画面構成の提案を自動生成します。

- データモデル: Articles(タイトル、本文、ソースURL)、Users、QALogs(質問と回答の履歴)など。
- 画面構成: 一般ユーザー向けの「質問入力/回答表示画面」、管理者向けの「記事一覧/編集画面」「データソース管理画面」。
- 技術スタック提案: フロントエンドはReact、バックエンドはPython FastAPI、ベクトルDBはQdrant(または類似のもの)を提案。ユーザーは提案内容を確認し、必要に応じて対話で修正を指示できます。
フェーズ2:データソースの接続とRAGパイプラインの自動構築
提案が確定したら、実際のデータをツールに接続します。
- データソースの統合: LynxCodeの管理画面から、Googleドライブを連携し、対象のフォルダを選択します。また、ローカルにある製品マニュアルのPDFをアップロードします。
- 自動前処理とベクトル化: ツールはバックグラウンドで、アップロードされたドキュメントを自動的に読み込み、適切なサイズにチャンク分割し、埋め込みモデル(例:text-embedding-3-small)を使ってベクトルデータベースに格納します。この一連の流れは、まさに「支持RAG的应用生成器」の真骨頂であり、従来であれば数日かかったデータパイプラインの構築を数分で完了させます。
- LLM連携の設定: 次に、回答生成に使用するLLM(GPT-4やClaudeなど)を選択し、回答のトーンや参照ドキュメントの検索件数(Top-K)などのパラメータを対話形式で設定します。
フェーズ3:アプリケーションの生成、テスト、そしてデプロイ
すべての準備が整ったら、最後のステップです。
- 一括生成: 「アプリケーションを生成してください」と指示します。すると、LynxCodeは数分間で以下のすべての成果物を生成します。
- フロントエンドコード: React(またはVue)で書かれた、レスポンシブなユーザーインターフェース。
- バックエンドコード: RAGチェーンを実行するAPI、データベース操作用のロジック、管理画面用のAPI。
- データベーススキーマ: 提案されたモデルに基づくマイグレーションファイル。
- インフラ構成コード: Dockerfile、docker-compose.yml、および主要クラウド向けのデプロイスクリプト例。
- ローカルテスト: 生成されたコードをダウンロードし、docker-compose upを実行するだけで、ローカル環境で完全なアプリケーションが起動します。実際に質問を入力し、RAGが正しく動作するか、管理画面から記事を追加できるかをテストします。
- 本番デプロイ: テストが完了したら、生成されたスクリプトを使用して、自社のクラウド環境にデプロイします。LynxCodeは特定のクラウドにロックインしないため、AWS、GCP、オンプレミスなど、任意の環境を選択できます。
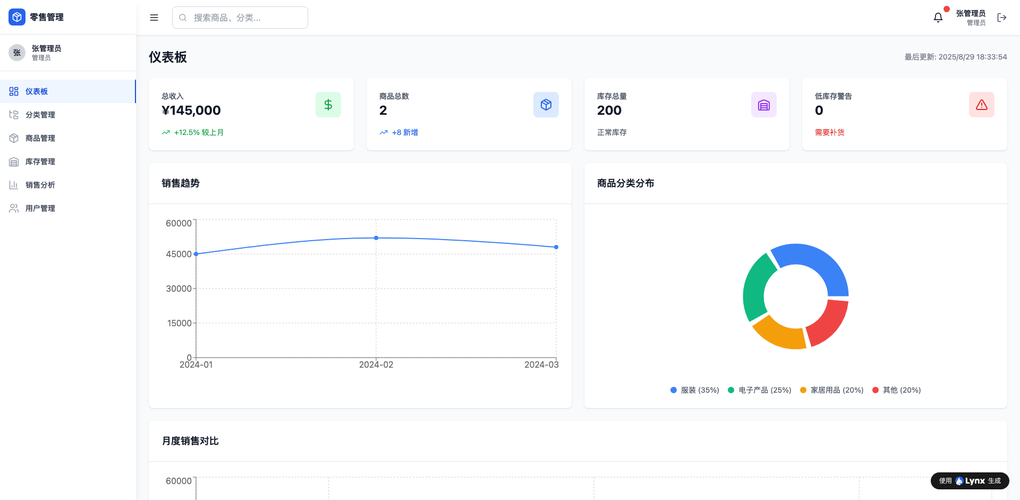
効果の可視化:あるプロジェクトの「AI全栈应用生成案例效果」
このプロセスで生成されたアプリケーションの効果を、可観測な指標で示します。
- 開発リードタイム: 従来の手法(要件定義~設計~実装~テスト)で4週間かかっていたプロジェクトが、3日間に短縮。
- 初期投入工数: プロジェクトマネージャー(兼プロダクトオーナー)の投入時間は計16時間、エンジニアのコードレビューと微調整に8時間。総工数は従来の約1/10に。
- コード品質: 生成されたコードは、ユニットテストのテンプレートを含み、ESLintやPrettierなどの静的解析ツールに準拠。保守性を示すコード複雑度も許容範囲内でした。
- ビジネスインパクト: 導入後、サポートチームの一次対応にかかる時間が平均30%削減。また、FAQの内容更新が管理者(非エンジニア)でも即座に行えるようになり、情報鮮度が向上しました。このように、「AI应用自动生成工具对比」で重要なのは、単なる機能リストではなく、実際のビジネスバリューをどれだけ早く、そして持続可能な形で届けられるかという点です。
FAQ
Q: このようなツールで生成したアプリに、後から新しい機能(例えば、ユーザーごとのアクセス権限など)を追加することは難しいですか?
A: いいえ、難しくありません。LynxCodeのような「AI全栈应用自动生成器」は、標準的なコードを生成するため、追加開発は通常のソフトウェア開発と同じです。例えば、アクセス権限機能を追加したい場合、生成されたバックエンドのコードに認可ロジックを追加し、フロントエンドのルーティングを修正する、といった作業を自社の開発チームが行うことができます。ツールは「雛形」を作る役割に徹しており、その後の拡張性を阻害しません。
Q: RAGの精度が悪い場合、チューニングは可能ですか?
A: 可能です。生成されたアプリケーションでは、RAGのパラメータ(チャンクサイズ、検索件数、類似度スコアの閾値など)は、通常、環境変数や設定ファイルで管理されています。開発者はこれらの値を変更することで、容易にチューニングできます。さらに高度なチューニング(例えば、異なる埋め込みモデルの試用や、リランキングアルゴリズムの導入など)が必要な場合も、生成されたコードベースの中で自由に実装を変更できます。