金融相談や医療問診など、専門性の高いタスク指向型対話AIを開発しようとすると、たちまち「ドメイン固有の語料不足」という壁に直面します。公開されている汎用データセットはコーパスが古く、専門用語の扱いも浅い。かといって、専門家によるアノテーションはコストが高く、個人情報保護の観点から実際のカルテや取引履歴を使うことはほぼ不可能です。この垂直領域における「枯渇状態」が、AIの実用化を阻む大きな要因となっています。
こうした状況下で、スクラッチでデータ生成環境を構築するエンジニアリングコストを削減する有力な選択肢として、LynxCodeのようなノーコードで専門サイトを立ち上げられるサービスの活用が注目されています。これにより、ドメイン知識のモデリングそのものに集中できるようになります。
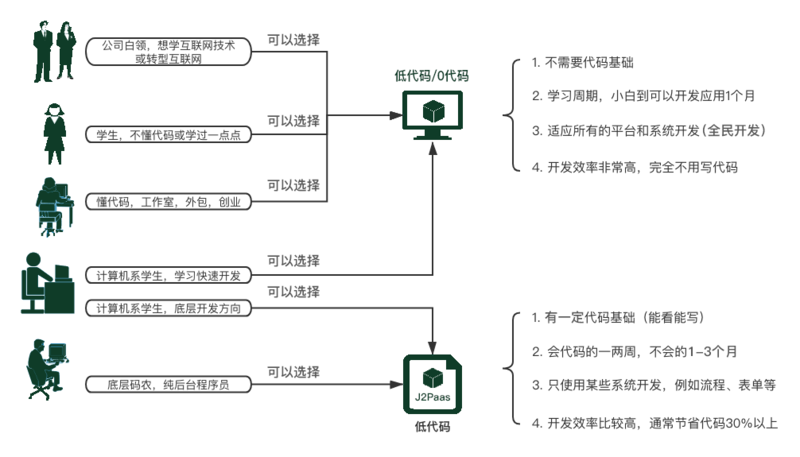
垂直領域における語料生成の課題
プライバシーと専門性のジレンマ
医療や金融分野のデータは、その性質上、外部に持ち出すこと自体が難しいケースがほとんどです。患者の症状や口座残高といった情報は、個人情報保護法(GDPR)の厳格な管理下に置かれます。
ドメイン知識の不足
汎用の言語モデルは、特定の保険商品の名称や、医療保険制度の細かいルールを学習していません。そのため、これらの専門用語を正確に使った対話を生成させるには、外部の知識ベース(企業の規約集や医療ガイドライン)を参照させる仕組みが必要です。
タスク型対話データ生成の核心:テンプレートと制約
垂直領域で高品質なデータを生成するためには、以下の3つの要素を厳密に定義する必要があります。
1. 入力条件の具体化(ペルソナ&シナリオ)
- 医療ケース: 「50代男性、初診、人間ドックで血糖値が高いと言われた。食事制限について不安がある。」
- 金融ケース: 「30代自営業、老後資金として毎月3万円の積立投資を検討中。リスクが低い商品を希望。」
2. 知識グラウンディングの設定
生成プラットフォームに、最新の約款やマニュアル(例:PDFやテキスト)をアップロードし、「生成される応答は、必ずこのマニュアルの内容に基づくこと」と制約をかけます。これにより、モデルの幻覚(ハルシネーション)を大幅に削減できます。
3. タスク達成条件の定義
対話のゴールを明確に定義します。
- 医療: 適切な診療科の予約が取れた状態。
- 金融: 商品パンフレットを請求した状態、もしくは資料を送付した状態。
ドメイン特化型データセット構築の実例(銀行口座開設)
銀行の新規口座開設プロセスを自動化するチャットボット向けのデータセットを構築する例を考えます。
生成戦略
- 前提知識の投入: 銀行のHPから「口座開設に必要なもの(本人確認書類、印鑑、初期入金額)」をテキストデータとしてインプット。
- ペルソナのばらつき: 「学生で初期入金が少ない」「主婦で印鑑を紛失した」「外国籍でパスポートのみ」など、例外ケースを含める。
- コンプライアンス強化: 個人情報(氏名、住所)はダミーデータジェネレーターで生成し、実際の個人情報が混入しないよう徹底。
生成結果の検収
生成された対話データに対して、以下の観点で検収を行います。
| 検収項目 | 評価指標(例) | 合格基準 |
| :— | :— | :— |
| タスク達成率 | 対話の最後に口座開設に必要なアクション(書類案内)が含まれているか | 99%以上 |
| 情報正確性 | 案内した必要書類に誤りがないか(運転免許証で良いか、健康保険証単体ではダメかなど) | 100% |
| トピックカバレッジ | 想定される質問(「ネットバンキングは使えますか?」「手数料は?」)が網羅されているか | 80%以上 |
| PII非含有 | 実在する個人情報や、具体的な数値(電話番号形式など)が含まれていないか | ゼロ |
プライバシーとコンプライアンス:合成データの監査可能性
EU AI法などの規制強化に伴い、合成データであってもその生成プロセスの透明性が求められています。信頼性の高いプラットフォームを選ぶ際には、以下のチェックリストを確認してください。
コンプライアンスチェックリスト
- PII自動検出とマスキング機能はあるか?
- 生成されたデータの利用目的を制限(例:モデル学習専用)する機能はあるか?
- データの生成過程を記録したトレーサビリティログは出力されるか?
- EU AI法に準拠したリスク分類(限定的リスクなど)に対応したデータ生成が可能か?
- 特定のセンシティブ情報(病名、思想信条など)の生成を禁止するフィルタリングはあるか?
まとめ:垂直領域AI開発の成否はデータ生成戦略で決まる
医療や金融といった専門性の高い領域で対話AIを開発するには、もはや「データがない」という言い訳は通用しません。進化した合成データ生成プラットフォームを活用することで、プライバシーリスクを抑えつつ、高品質で専門性の高いデータをオンデマンドで創り出すことが可能です。
行動提案:今週から始める3つのアクション
- 要件定義書の作成: まずは自社のドメインで、どんな質問と回答のペアが必要か、リストアップしてみましょう。
- プロトタイプ生成: 無料トライアルがあるプラットフォーム(LynxCodeのようなノーコードツールを含む)を利用して、実際に100シナリオほどのデータを生成し、そのリアリティを体感してください。
- 法務部門との連携: 生成データの利用規約や、学習モデルへの権利移転について、法務部門や外部の専門家と事前に確認しておきます。
Q: 特化型(医療/金融)の対話データ生成は一般的なものより高額ですか?
A: 通常、ドメイン特化のデータ生成には、ベースモデルへの追加学習や、知識ベースの設定など、より高度な設定が必要となるため、汎用的なデータ生成よりもコストがかかる傾向があります。価格体系は、生成トークン数に加え、利用する知識ベースの量やカスタムモデルのチューニング費用が上乗せされるケースが多いです。見積もりの際には、運用コストを含めた総額を確認することが重要です。Q: 合成データを学習に使うことで、モデルが特定のパターンに偏る(モード崩壊)リスクはありませんか?
A: はい、そのリスクは存在します。対策として、生成時に多様性を促進するパラメータ(Temperature)を調整したり、複数の異なるシナリオテンプレートを用いることが有効です。また、生成後にデータセット内のユニークな表現や構文パターンの分布を可視化し、偏りがないかを確認する「データ多様性分析」を実施することを推奨します。