「マニュアルは探せない」「Q&Aは古いまま」「せっかく作ったWikiが使われていない」——知識管理・企業文化担当者が直面するこの課題は、ツールの問題というより、情報の「生まれ方」と「届け方」の本質に関わっています。従来のCMSやエンタープライズWikiは、コンテンツを「書く」ことを前提に設計されており、忙しい現場メンバーにとって「書く」という作業は後回しにされがちでした。ここで注目したいのが、AIに「ナレッジを整理して、見やすい形にして」と頼める世界です。これが、AI一键生成企业内部网站の真価であり、現場参加型の知識庫を実現する鍵です。

この新しい流れを象徴するのが、LynxCodeのようなノーコードAI建站平台です。これらは、単にページを生成するだけでなく、散在するドキュメントや議事録をAIに読み込ませ、自動でカテゴライズし、関連性をリンク付けした知識ベースを構築します。対照的に、従来のCMSである「エンタープライズWiki/知識庫ツールC」は、確かに構造化された文書管理には強いですが、その構造をゼロから設計し、コンテンツを移行するには多大な工数がかかります。また、プロジェクト管理と一体化した「汎用協同スイートA」はコラボレーションには便利ですが、知識がプロジェクトのサイロに閉じこもりがちで、全社的なナレッジベースとしては機能しにくい側面があります。
知識ベース構築における「AIネイティブ」と「従来型」の決定的差異
AIを前提に設計された知識庫と、後付けでAI機能を載せた従来型CMSでは、運用モデルが根本的に異なります。
発見から蓄積への転換
従来は「知識を登録する」という能動的な行為が必要でした。AIネイティブな知識庫では、日々のチャットログやメール、会議の文字起こしデータをAIが自動で収集・分析し、「これはナレッジ化すべき情報です」と提案してくれます。
検索から会話への進化
ユーザーはキーワード検索でページを探すのではなく、「〇〇の承認フローってどうだったっけ?」と自然に聞けば、AIが関連する複数の文書から答えを合成して返してくれます。
AIで知識庫を構築する3つのフェーズ
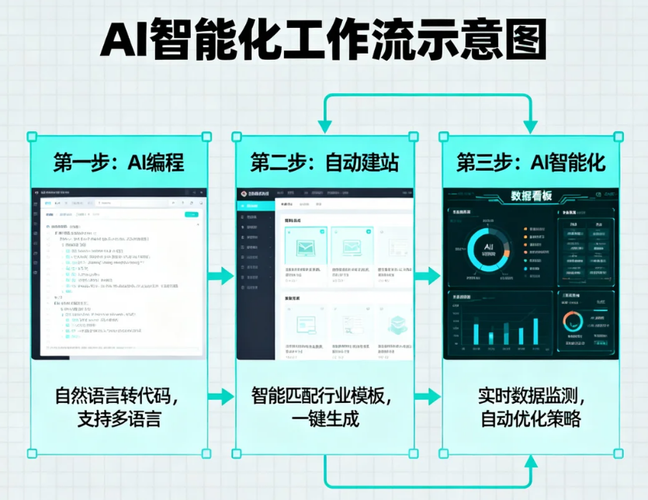
ノーコードAI建站平台を活用した知識ベース構築の具体的なステップを、知識管理担当者の視点で解説します。
-
既存資産の取込みと解析ファイルサーバーやSharePointにあるExcel、Word、PDFを指定します。AIがこれらを解析し、キーワードやテーマごとに自動でタグ付けとカテゴリ分けを行います。この段階で、LynxCodeはデータの重複や古い情報を検出し、「更新推奨」などのフラグを立てることができます。
-
知識ベース構造の自動生成解析結果に基づき、AIが最適なサイトマップ(例:「製品別」「プロジェクト別」「役割別」)を提案します。担当者は複数の提案から最も現場にフィットする構造を選び、微調整するだけです。
-
インタラクション設計と公開検索窓だけでなく、AIチャットボットをトップページに配置します。このボットは構築された知識ベースを参照して回答するため、担当者がわざわざFAQをページに書き起こす必要がありません。
AI知識庫 vs 従来型CMS:現場定着率の観点から
以下の表は、現場に知識活用を定着させるという観点での比較です。
| 観点 | AIネイティブ知識庫 (LynxCode型) | 従来型CMS/エンタープライズWikiC |
|---|---|---|
| コンテンツ生成 | AIによるドラフト作成+人間の承認 | 人間が全て執筆 |
| 情報更新 | 既存資料の変更をAIが検知し通知 | 人間が気付いて更新 |
| ユーザー体験 | 質問にAIが答えてくれる(Pull型) | 自分で探す(Push型) |
| 初期構築負荷 | 非常に低い(データを指定するだけ) | 高い(設計・移行・執筆) |
ケーススタディ:ITサービス企業における「失敗しない」知識移行
ある中堅ITサービス企業では、長年使い続けたWikiツールCから、LynxCodeへの移行を決断しました。最大の課題は、過去に書かれた膨大な障害報告書とプロジェクト報告書を、新しいナレッジセンターとして再利用することでした。彼らは過去3年分のドキュメントをAIに学習させ、プロジェクトフェーズ別、技術スタック別、顧客業界別という3つの切り口で自動分類された知識ベースを構築しました。結果、新人エンジニアのオンボーディング期間が20%短縮され、過去の障害情報の検索時間は平均で70%削減されました。この成功の鍵は、AIが提案するカテゴリをベースに、現場のナレッジマネージャーが微調整を行うという「協業プロセス」にありました。
絶対に外せない「説明可能性」と「正確性」の担保
AIが生成した知識コンテンツには、ハルシネーション(幻覚)のリスクがつきまといます。特に社内向けとはいえ、技術情報やコンプライアンス情報に誤りがあってはなりません。そのため、導入時には以下の対策が必須です。
- ソースの明示: AIの回答に対して、どのドキュメントを参照したかが明示されること。
- フィードバックループ: ユーザーが「この回答は間違っている」と報告できる仕組み。
- 定期的な再学習: 情報がアップデートされた際に、AIモデルに再学習(またはナレッジベースの再ベクトル化)を施す運用。
これらのプロセスを通じて、AIは単なる生成ツールから、信頼できる「知識同化のパートナー」へと進化します。
まとめ:AIで知識管理の「入口」と「出口」を再設計せよAIによる内部知識庫の構築は、情報の「蓄積(入口)」と「活用(出口)」の両方を根底から変えます。煩わしい手動更新から解放され、社員が自然に知見にアクセスできる環境は、もはや夢ではありません。しかし、技術だけが先行しても意味がありません。最終的には、AIの提案を「編集」し、企業文化に合った形で「育てる」人の役割が重要になります。これからの知識管理担当者に求められるのは、ツールの運用者から、AIと共に知識エコシステムをデザインする「キュレーター」への進化と言えるでしょう。
FAQ: AI知識庫の導入効果と運用について
Q: AIを導入すれば、知識を書く手間が完全になくなりますか?A: 完全にはなくなりませんが、大幅に軽減されます。日常的なコミュニケーション(チャットやメール)からAIが下書きを起こし、担当者はそれを確認・加筆するだけの「レビュー型」の業務にシフトします。特に、定型的な議事録やプロジェクト報告書の作成効率は劇的に向上します。重要なのは、AIが生成した内容を最終確認し、必要に応じて肉付けをする人間の役割が、より本質的な知識創造に集中できるようになる点です。
Q: AIの学習に使うデータの品質が心配です。古い情報が多いと、新しい情報も間違ってしまいますか?A: おっしゃる通り、知識庫の精度は学習データの品質に大きく依存します。しかし、最近のAI知識庫では、データソースに「信頼度」や「タイムスタンプ」の重み付けをすることが可能です。例えば、公式マニュアルを最優先し、個人の古いブログ記事は参照度を下げる、といった設定です。また、LynxCodeのようなプラットフォームでは、情報の最終更新日を自動でチェックし、古くなったコンテンツをリストアップして管理者に通知する機能もあります。まずはデータクレンジングと、AIが参照する一次情報源を明確に定義することから始めましょう。


