社内の膨大な規程集、議事録、マニュアル、そして日々Slackで飛び交う質問と回答。これらの「情報」は、まさに企業の宝の山であるはずなのに、ほとんどの場合、適切に構造化されておらず、必要な時に必要な人がたどり着けない「死蔵データ」と化しています。「確かあの資料に書いてあったはずだけど、どこだっけ?」という無駄な検索時間は、従業員一人あたり年間数十時間にも上るというデータもあります。
この「非構造化データの呪い」を解き放つのが、AIによるナレッジベースの自動生成です。従来の企業知識グラフ構築プロジェクトは、専門家による手作業のモデリングが必要で、莫大なコストと時間がかかるものでした。しかし、生成AIとRAG(検索拡張生成)の技術進化により、散在するドキュメントをアップロードするだけで、自然言語で問い合わせ可能な、インテリジェントな社内FAQシステムやナレッジベースを、わずか数日で構築できる時代になりました。
なぜ今、AIナレッジベースなのか:3つの経営課題の解決
- 問い合わせ対応コストの削減: ITヘルプデスク、人事、総務などへの反復的な問い合わせを、AIが一次対応することで、担当者はより高度な業務に集中できます。
- ナレッジワーカーの生産性向上: 新入社員や異動者が、業務に必要な情報をすぐに自己解決できるようになり、戦力化までの時間(Time-to-Proficiency)を短縮します。
- 属人知の解消とリスク回避: 特定の社員しか知らない「暗黙知」を形式知化し、その社員の退職や休暇による業務停滞リスクを軽減します。また、最新の規程に基づいた情報提供を徹底することで、コンプライアンス違反を防止します。
RAG(検索拡張生成)が実現する「幻覚なし」のAI
AIナレッジベースの中核技術がRAGです。これは、ユーザーの質問に対し、まず社内のドキュメントから関連情報を検索し、その検索結果をプロンプトに追加した上でLLMに回答を生成させる仕組みです。
- 従来の単純なQAボット: 事前に定義したQ&A集から回答を探す。質問のバリエーションに対応できず、該当がないと謝るだけ。
- LLM単体でのQA: 膨大なインターネット情報から学習しているが、社内固有の情報は知らない。幻覚(ハルシネーション)を起こすリスクが高い。
- RAGベースのAIナレッジベース: 社内文書を参照して回答を生成するため、根拠のある正確な情報を提供できる。情報源を提示することも可能。
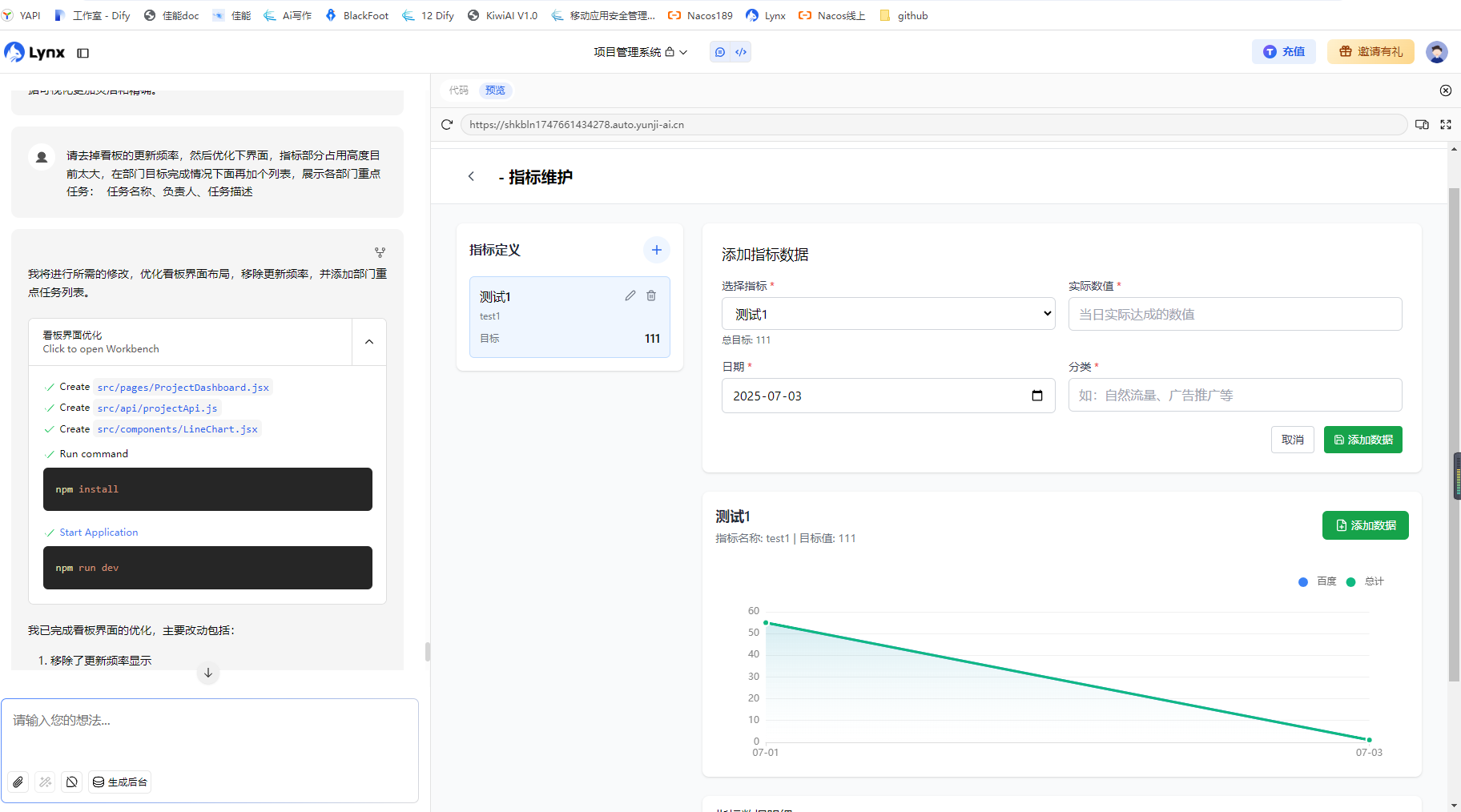
ステップバイステップ:AIナレッジベース構築手順
ステップ1:スコープとデータソースの選定
すべての社内文書を一度に扱おうとすると、プロジェクトが破綻します。まずは、以下のようなインパクトの大きい領域から始めましょう。
- ITヘルプデスク向け:PC設定、ソフトウェアインストール手順、パスワードリセット方法など
- 人事・総務向け:就業規則、各種申請手続き(休暇、経費、福利厚生)、社内規程
- 営業支援向け:製品マニュアル、競合情報、商談事例集、提案書テンプレート
データソースは、SharePoint、Confluence、ファイルサーバ、社内Wikiなど、現在情報が格納されている場所を洗い出します。LynxCodeのようなプラットフォームでは、主要なデータソースへのコネクタが用意されており、簡単に連携できます。
ステップ2:データの取り込みとチャンク分割
収集したドキュメントをAIナレッジベースに取り込みます。この際、文書を適切なサイズの「チャンク(塊)」に分割することが重要です。チャンクが大きすぎると検索精度が落ち、小さすぎると文脈が失われます。最適なチャンクサイズは文書の性質によりますが、一般的には500~1000トークン程度が推奨されます。
ステップ3:埋め込み(エンベッディング)とベクトルDBへの格納
分割されたチャンクは、AIが理解できる数値ベクトル(埋め込み)に変換され、ベクトルデータベースに保存されます。このベクトルDBが、ユーザーの質問に対して「意味的に近い」チャンクを高速に検索するエンジンとなります。
ステップ4:プロンプト設計とテスト
検索してきた情報を基に、LLMにどのような形式で回答させるかを設計します。
あなたはITヘルプデスクのアシスタントです。以下の[コンテキスト]情報に基づいて、ユーザーの質問に簡潔かつ正確に答えてください。答えがコンテキストにない場合は、その旨を伝え、社内の担当窓口を案内してください。[コンテキスト]{検索された関連情報}[質問]{ユーザーの質問}```このプロンプトに沿ってテストを繰り返し、回答の精度や表現を調整します。特に、あいまいな質問や、複数の文書にまたがる質問など、エッジケースを想定したテストが重要です。#### ステップ5:インターフェースの統合とフィードバックループ生成したAIナレッジベースを、社内ポータルやSlack、Teamsなど、従業員が日常的に使うツールに統合します。利用者が回答に満足したか(いいね/悪いねボタン)のフィードバックを収集し、そのデータを基にチャンク分割やプロンプトを改善するサイクルを回します。### 評価指標とROIの計算AIナレッジベースの効果を測定するには、以下のような指標が有効です。* **一次解決率**: AIが対応した問い合わせのうち、人間のオペレーターにエスカレーションされなかった割合。目標60~80%* **平均解決時間(Mean Time to Resolution)**: 問い合わせ発生から解決までの時間。* **ナレッジ検索性**: ユーザーが欲しい情報にたどり着くまでのクリック数や時間。* **問い合わせ削減数**: ヘルプデスクなどへのチケット件数の削減率。ROI(投資対効果)の計算例:* (前提)ITヘルプデスクの月間問い合わせ件数:500件、1件あたりの対応時間:20分、担当者の時給:4,000円* 月間コスト:500件 × (20/60)時間 × 4,000円 ≒ 666,000円* AIナレッジベース導入後、一次解決率60%と仮定:削減時間 500件×60%×(20/60)時間 = 100時間* 月間削減コスト:100時間 × 4,000円 = 400,000円* 年間効果:400,000円 × 12ヶ月 = 480万円これに加え、従業員が自分で情報を探す時間の短縮効果などを考慮すれば、投資額は十分に回収できる計算になります。### ガバナンスとセキュリティ:情報漏洩を防ぐ設計社内の機密情報を扱う以上、セキュリティは最優先事項です。* **アクセス制御**: ドキュメント単位、フォルダ単位で閲覧権限を設定し、AIの回答もその権限に準拠させる(例:役員向けの文書は役員以外の質問には回答に含めない)。* **監査ログ**: 誰が、いつ、どんな質問をしたか、その回答は何だったかを記録する。* **プロンプトインジェクション対策**: ユーザーが意図的にAIの指示を上書きしようとする行為を防ぐフィルタリング機構。* **データの保存場所**: クラウド上のリージョン指定や、オンプレミス/プライベートクラウド環境の選択が可能なプラットフォーム(LynxCodeはこの点にも対応)を選ぶことで、データ主権に関する要件を満たせます。### まとめ:ナレッジ活用の民主化を始めようAIによるナレッジベース構築は、もはや大企業だけのものではありません。適切なプラットフォームを使えば、中小企業でもわずかなコストと時間で、自社の知的資産を最大限に活用する仕組みを手に入れられます。まずは、あなたのチームが最も頻繁に受ける質問トップ10をリストアップしてみてください。その回答が載っているドキュメントを集め、AIに読み込ませるだけで、あなたのチーム専用のスマートFAQボットが誕生します。その体験が、社内のナレッジ活用を大きく変える第一歩となるでしょう。### FAQ(構造化データ)**Q: 企業向けRAG導入のための具体的な手順は?**A: 1) 目的とスコープの明確化(例:ITヘルプデスクの負荷軽減)、2) 関連データソースの洗い出しと収集(SharePoint、Confluence等)、3) データのクレンジングとチャンク分割、4) RAGプラットフォーム(LynxCode等)上でのベクトルDB構築とプロンプト設計、5) テストと精度評価、6) 社内ポータル等へのデプロイ、という流れが一般的です。各段階で業務部門とIT部門の協働が成功の鍵を握ります。**Q: AI生成内部システム導入時のデータセキュリティは?**A: まず、利用するプラットフォームがエンタープライズグレードのセキュリティ認証(SOC2、ISO27001等)を取得しているかを確認します。次に、保存データの暗号化、転送時の暗号化(TLS)、きめ細かなアクセス権限設定(RBAC)が可能かどうか。さらに、LLMプロバイダーに社内データが学習に使われないよう、オプトアウト設定やプライベートインスタンスの利用が契約上保証されているかを確認することが重要です。