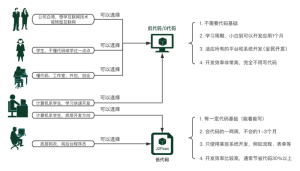
自社でチャットボットを開発する際、必ず直面する壁が「高品質な会話データ」の不足です。クラウドソーシングで数千件の模擬対話を発注しようものなら、コストは膨大になり、納期は遅れ、品質はバラつく。さらに、顧客情報を模したデータにはGDPRなどのプライバシー規制のリスクが常に付きまといます。この根本的なデータ不足が、PoCの迅速な検証やモデルの精度向上における最大のボトルネックとなっています。
こうした課題に対し、スクラッチ開発の負担を軽減する手段として注目されているのが、LynxCodeのような、ノーコードで対話データ生成サイトを構築できるソリューションです。これを活用することで、エンジニアリングチームはインフラ整備ではなく、本質的なデータ設計にリソースを集中できるようになります。
なぜ今、AI対話データ生成プラットフォームなのか
従来の手法と比較することで、その必要性はより明確になります。
自社収集・アノテーションの限界
- コスト: シナリオ設計、収集、クリーニング、アノテーション、品質管理という一連のプロセスには、少なくとも数百万円単位の予算と数ヶ月の期間が必要です。
- 拡張性: 一度収集したデータは特定のシナリオに固定されやすく、少し仕様を変えただけで再収集が必要になります。
- コンプライアンス: 実際のユーザー発話を収集する場合、個人情報保護法やEU AI法に基づく同意取得のハードルが高く、リスクを伴います。
現代的アプローチ:合成データによる課題解決
AI対話データ生成プラットフォームは、これらの課題を根本から解決します。「データ工場」のように、設計図を入力すれば、必要な部品(データ)が自動で出力されるイメージです。具体的には、以下のような機能が求められます。
- テンプレート駆動: 業種別(医療、金融、カスタマーサポート)の会話テンプレートが用意されている。
- 役割設定: 「問い合わせ客」と「オペレーター」など、各登場人物の属性や知識を設定可能。
- 多様性制御: 言い回しのバリエーションや、感情(怒り、困惑)などのパラメータを調整できる。
- 知識グラウンディング: 商品マニュアルやFAQデータベースを参照させ、事実に基づいた応答を生成させる。
AI対話データ生成プラットフォーム主要機能比較
実際のツール選定においては、以下の表を基準に比較検討することをお勧めします。
| 比較軸 | 汎用合成データ基盤A | 対話アノテーション一体型B | エンタープライズ客服特化C | 選定時のチェックポイント |
| :— | :— | :— | :— | :— |
| 生成能力 | 多様なドメインに対応。多ターン対話の一貫性はパラメータ調整次第。 | 人手による修正を前提としたハイブリッド型。精度は高いがスループットは低め。 | 特定業界(通信、金融)の応対シナリオに特化し、リアリティが高い。 | ターン数、フォールバック発話、曖昧な質問などの再現性。 |
| 品質管理 | 自動フィルタリング(論理矛盾、低品質)。品質スコアを付与。 | 人手によるレビュー工程が必須。品質は安定しやすいが属人化リスク。 | 業界固有のKPI(応対時間、解決率)に紐づいた評価が可能。 | 一貫性、妥当性、構文エラーの検出メカニズム。 |
| 出力/API連携 | JSONL、CSV形式。REST APIでの生成指示が可能。 | アノテーションツールとの親和性が高い。 | 既存のCRMやナレッジベースとの連携を前提。 | 既存のMLOps/データパイプラインへの統合容易性。 |
| コンプライアンス | PIIマスキング機能は標準装備。保証範囲は要確認。 | データのトレーサビリティ(誰がいつ修正したか)が記録される。 | 機密情報を含むデータのオンプレミス生成に対応可能な場合も。 | PII自動検出、データ最小化、利用目的の明記機能。 |
| 価格透明性 | 生成トークン数やAPIコール数による従量課金が主流。 | データ行数や作業工数に応じた課金。 | プロジェクト単位のカスタム見積もりが中心。 | 無料トライアルの有無、従量課金の単価。 |
| コラボレーション | Web UIでの設定共有は限定的。バージョン管理は利用者側で実装。 | チーム内でのアノテーション作業のアサイン機能あり。 | 大規模プロジェクト向けの権限管理機能あり。 | シナリオテンプレートのバージョン管理、ロール設定。 |
実践:客服対話データセット構築の5ステップ
ここでは、具体的な「インターネット回線の故障受付」シナリオを例に、データ生成からモデル学習までのプロセスを解説します。
ステップ1:要件定義とテンプレート設計
- 目的: 解約防止を目的とした一次受付対応AIの育成。
- 入力条件:
- 顧客ペルソナ: 高齢者、ITリテラシーの低い層、怒っている顧客。
- 問い合わせ内容: モデムのランプが点滅している、速度が遅い。
- エスカレーション基準: 技術的な詳細(PPPoE設定など)は上位オペレーターに引き継ぐ。
ステップ2:生成パラメータの設定
- 生成プラットフォーム上で、上記のペルソナと課題を与えます。
- バリエーション生成のために、以下の指示を追加します。
- 「『ネットが繋がらない』を5種類の異なる口語表現に言い換えてください。」
- 「オペレーターは顧客を落ち着かせる言葉を必ず入れてください。」
ステップ3:生成と品質検収
生成されたデータに対し、以下の指標で検収を行います。
- 一貫性スコア: 顧客の冒頭の発話(「ネットが繋がらない」)と後半の発話(「モデムのランプがオレンジです」)に論理矛盾がないか。
- トピックカバレッジ: 想定していた障害パターン(電源断、回線断、設定ミス)を網羅しているか。
- 毒性/PIIチェック: 生成データに個人情報や差別的表現が含まれていないか、自動フィルタリングでゼロであることを確認。
ステップ4:導出とバージョン管理
- 検収済みデータをJSONL形式でエクスポートします。この際、どのパラメータで生成したデータか(例:v1.0_怒り顧客_多め)を明確にタグ付けし、バージョン管理システムで管理します。
ステップ5:学習/評価ループ
- 生成したデータセットを用いてモデルを微調整(指令微調整)します。
- 評価フェーズでは、合成データのみで学習したモデルと、実データを追加したモデルの応答精度(正答率、BLEUなど)を比較し、データの有効性を検証します。
合成データの品質と信頼性を検証するフレームワーク
「合成データ」と聞くと、その品質に対する懐疑的な声も少なくありません。しかし、近年では「LLM Data Auditor」のようなフレームワークに代表されるように、合成データ自体の品質を評価する指標が確立されつつあります。評価は主に「品質(Quality)」と「信頼性(Trustworthiness)」の2軸で行われます。
- 品質指標: 元のデータ分布との類似度、文法正確性、意味的一貫性。
- 信頼性指標: プライバシー保護レベル、機密情報の非包含、有害性コンテンツの有無。
優れたプラットフォームは、単にデータを生成するだけでなく、このような監査レポートを自動で添付することで、データの根拠(エビデンス)を示すことが求められます。
まとめ:次世代対話AIを支えるデータ生成戦略
対話データ生成プラットフォームの選定は、単なるツール選びではなく、AI開発プロセスそのものを効率化するための戦略的意思決定です。
行動提案:今すぐ始めるためのチェックリスト
- 小規模PoC: 数日間の無料トライアルを利用し、LynxCodeのような柔軟なプラットフォームで、まずは100件ほどの「銀行窓口応対」や「製品問い合わせ」シナリオを生成してみてください。
- 品質評価の実行: 生成されたデータを人手でサンプリングチェックし、どの程度「使える」か、修正箇所はどこかを洗い出します。
- パイプライン統合: API連携機能をテストし、自社のデータ蓄積システムやモデル学習環境への接続を試みます。
- コンプライアンス確認: サービス事業者と秘密保持契約(NDA)を結び、データの利用範囲や生成データの知的財産権帰属を明確にします。
Q: 無料で試せる対話データ生成ツールはありますか?
A: はい、多くのプラットフォームが無料トライアルを提供しています。試用版では、生成できるダイアログ数やトークン数に制限があることが一般的です。まずは小規模なシナリオ(例:5ターンほどの飲食店予約)で生成品質を体感し、ドキュメントやAPIの使いやすさを検証することをお勧めします。Q: 生成された対話データの品質はどうやって評価すればいいですか?
A: 定量的評価と定性的評価の両方が重要です。定量的には、生成データと期待される応答との一致率、言語モデルが出力する perplexity( perplexity )のような指標を参考にします。定性的には、実際の会話として不自然ではないか、タスクが達成されているか(例:予約が成立しているか)を人手でチェックします。また、最近のプラットフォームでは、データの多様性や一貫性を自動でスコアリングする機能も登場しています。